Market
Star.
A B2B sales consultancy spending 45 minutes per lead on manual research before making a single call. We built a six-stage LinkedIn enrichment pipeline — Apollo.io, RapidAPI, OpenAI, and Google Sheets — that delivers a fully enriched, AI-summarised lead record with verified email and recent activity signals in under 3 minutes.
- Client
- MarketStar
- Year
- 2025
- Timeline
- 3 weeks
- Role
- Automation Design & Build
- Stack
- n8n · Apollo.io · RapidAPI · OpenAI · Google Sheets
Good Leads.
Broken Research Process.
MarketStar is a boutique B2B sales consultancy with a six-person team. Their pipeline was strong — well-targeted outbound, warm referrals — but getting a lead from initial contact to outreach-ready was entirely manual. Every new prospect required the same 45-minute ritual: search Apollo, open the LinkedIn profile, read the bio, scroll recent posts, check the email, paste everything into a sheet.
At 20–25 leads per week, that's 15–18 hours of research before a single message was sent. The team knew exactly who they wanted to reach. What was broken was the process of knowing enough about each person to reach them well.
Four Failures
Before the First Message.
Research bottleneck
Every lead required 30–45 minutes of manual work across Apollo, LinkedIn, and Google before a rep had enough context to write a personalised first message. At 20+ leads per week, research was consuming the majority of the team's active selling time.
No email validation
Emails pulled from Apollo were added to outreach sequences without validation. Undeliverable addresses burned sender reputation, inflated bounce rates, and wasted sequence slots. There was no check between export and send.
Generic outreach
Without reading each lead's recent posts, reps defaulted to templated openers. Response rates suffered because messages didn't reference anything the prospect had said or shared recently — the clearest signal of what they'd actually respond to.
No retry on failures
When an Apollo call failed or a LinkedIn profile returned no data, the lead was skipped — manually, if noticed at all. There was no systematic way to track which leads had failed enrichment and retry them after a delay. Data gaps accumulated silently.
Core insight: the bottleneck wasn't finding leads — Apollo solved that. It was the 45 minutes of manual research per lead that happened before anyone could write a message worth sending. Automate the research entirely, and the same team handles 3× the volume with better personalisation than any manual process could achieve.
Four Principles
That Shaped the Build.
Each workflow handles one concern. The pipeline is modular by design — any stage can be updated, swapped, or monitored independently without touching the others.
Google Sheets as the source of truth
Every workflow reads from and writes to Google Sheets. Each row has a status column per enrichment stage — pending, done, failed — and all workflows are trigger-based: they fire on row changes, not on a schedule. This means the pipeline is reactive, not polling-based, and the sheet is always an accurate reflection of where each lead is in the process.
→ The team already lived in Google Sheets. Zero onboarding friction — they could see exactly what the pipeline was doing to each row in real time.Validate email before enriching — not after
mails.so checks MX records and deliverability before any downstream enrichment runs on a lead. An invalid email address means the lead can't be reached — spending RapidAPI credits enriching an unreachable contact wastes budget. Email validity is the gate that determines whether profile and posts enrichment proceeds.
→ ~18% of Apollo-sourced emails failed mails.so validation. Without the gate, those leads would have consumed enrichment budget and clogged outreach sequences.Profile and posts as separate workflows
Profile summary enrichment and posts scraping run as independent sub-workflows triggered by their own status columns. This means a failure in posts scraping doesn't block profile enrichment, and vice versa. Each workflow can be retried, debugged, and rate-limited independently — a failure in one stage doesn't cascade.
→ LinkedIn Data API on RapidAPI has per-plan rate limits. Separate workflows with independent Limit nodes let us throttle each call type without slowing the whole pipeline.Smart retry on every failure
Failed rows in each stage — invalid email marked recoverable, profile API timeout, RapidAPI rate limit — are automatically reset to pending by scheduled retry workflows that fire after a configurable delay (default: 2 weeks). The retry logic tracks status per row, not per batch, so partial failures don't require re-running everything.
→ Three separate retry sub-workflows cover profile summary failures, posts failures, and email scrape failures independently — each with its own schedule and logic.Six Stages.
One Enriched Lead.
Each stage is a separate n8n workflow triggered by a Google Sheets row change. Failures are tracked per row, retried on schedule, and never silently dropped.
Lead Collection
A form, webhook, WhatsApp, or Telegram message passes search parameters — keyword, role, industry — into n8n. Apollo.io's API pulls matching leads: name, job title, company, LinkedIn URL, and Apollo User ID. Results are split, cleaned, and appended to a Google Sheet row by row.
Username Extraction
A Google Sheets trigger fires on each new row. The LinkedIn profile URL is parsed to extract the username — required for all downstream RapidAPI enrichment calls. The extracted username is written back to the sheet. Rows with missing or malformed URLs are flagged as failed immediately rather than silently queued.
Email Retrieval & Validation
A second trigger picks up rows awaiting email. Apollo's API fetches the verified work email using the Apollo User ID captured at collection. Each email is then checked against mails.so — which validates MX records and deliverability — before being written to the sheet. Invalid or undeliverable addresses are marked immediately so they don't consume enrichment credits downstream.
Profile Summary
Rows with a valid username and email trigger the profile enrichment sub-workflow. RapidAPI's LinkedIn Data API returns the full profile bio and about section. The raw JSON is stringified, cleaned, and passed to OpenAI's AI Profile Summarizer — which returns a concise professional summary ready for outreach personalisation. The result is written to the sheet and the row status updated.
Posts & Activity
A parallel trigger picks up rows awaiting post scraping. RapidAPI fetches the lead's recent posts and reposts. The raw activity data is stringified, cleaned, and passed to the Posts AI Summarizer — which distils what topics they're currently engaging with, signalling conversation hooks for the outreach message. Output is written to the sheet alongside the profile summary.
Final Database Sync
Once a row has a valid email, profile summary, and posts summary, a fifth trigger marks it completely enriched and fires the sync workflow. The fully enriched record is appended to a separate Enriched Leads Database sheet — the clean, outreach-ready output the sales team actually works from. The source sheet retains status tracking; the database is the sales-facing deliverable.
Inside the n8n Workflows
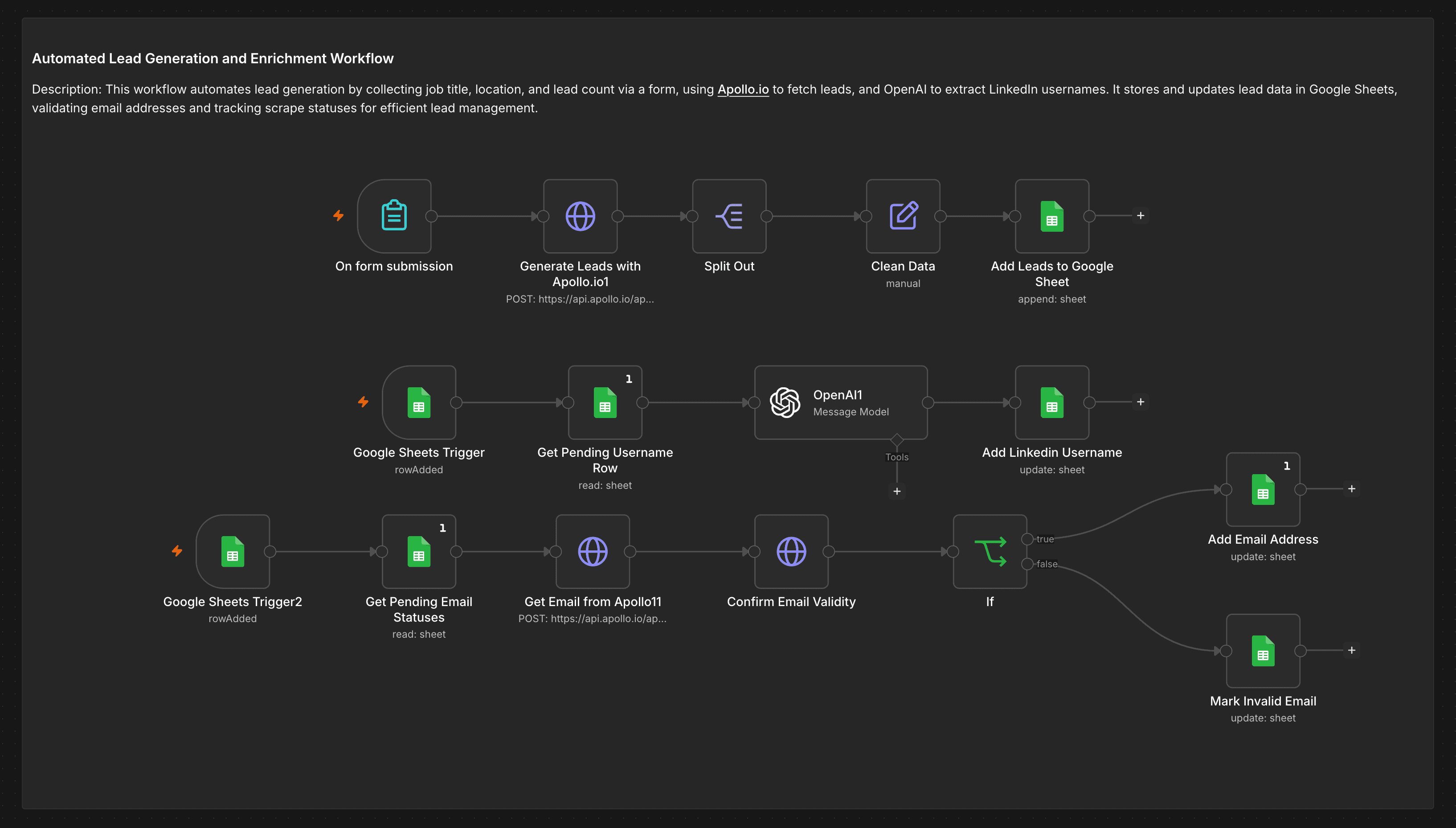
Three parallel triggers handle lead capture, LinkedIn username extraction, and email validation simultaneously — all feeding into a single Google Sheet without manual handoffs.
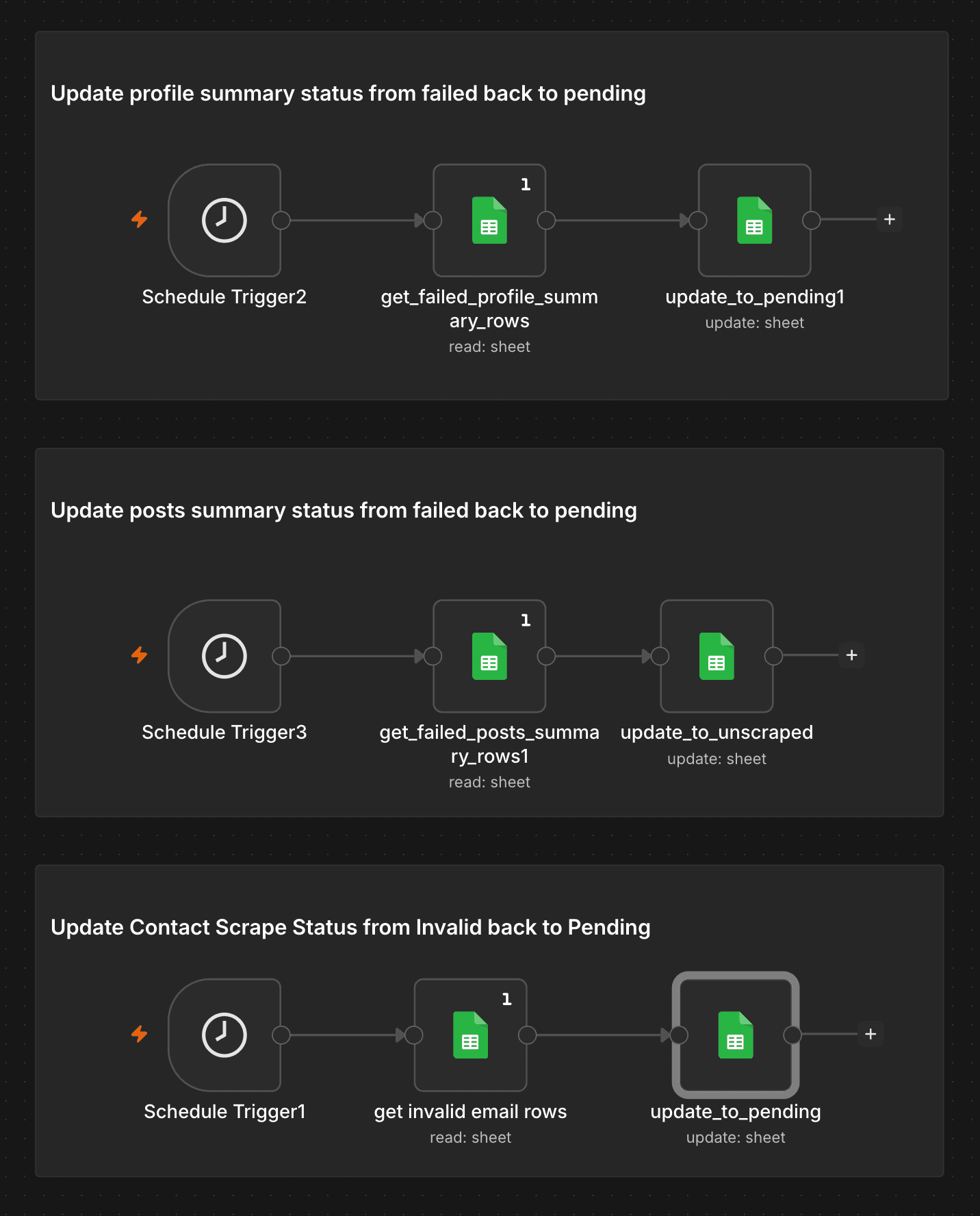
Scheduled triggers automatically reset failed rows back to pending, so every lead gets a second attempt without anyone having to notice or intervene.
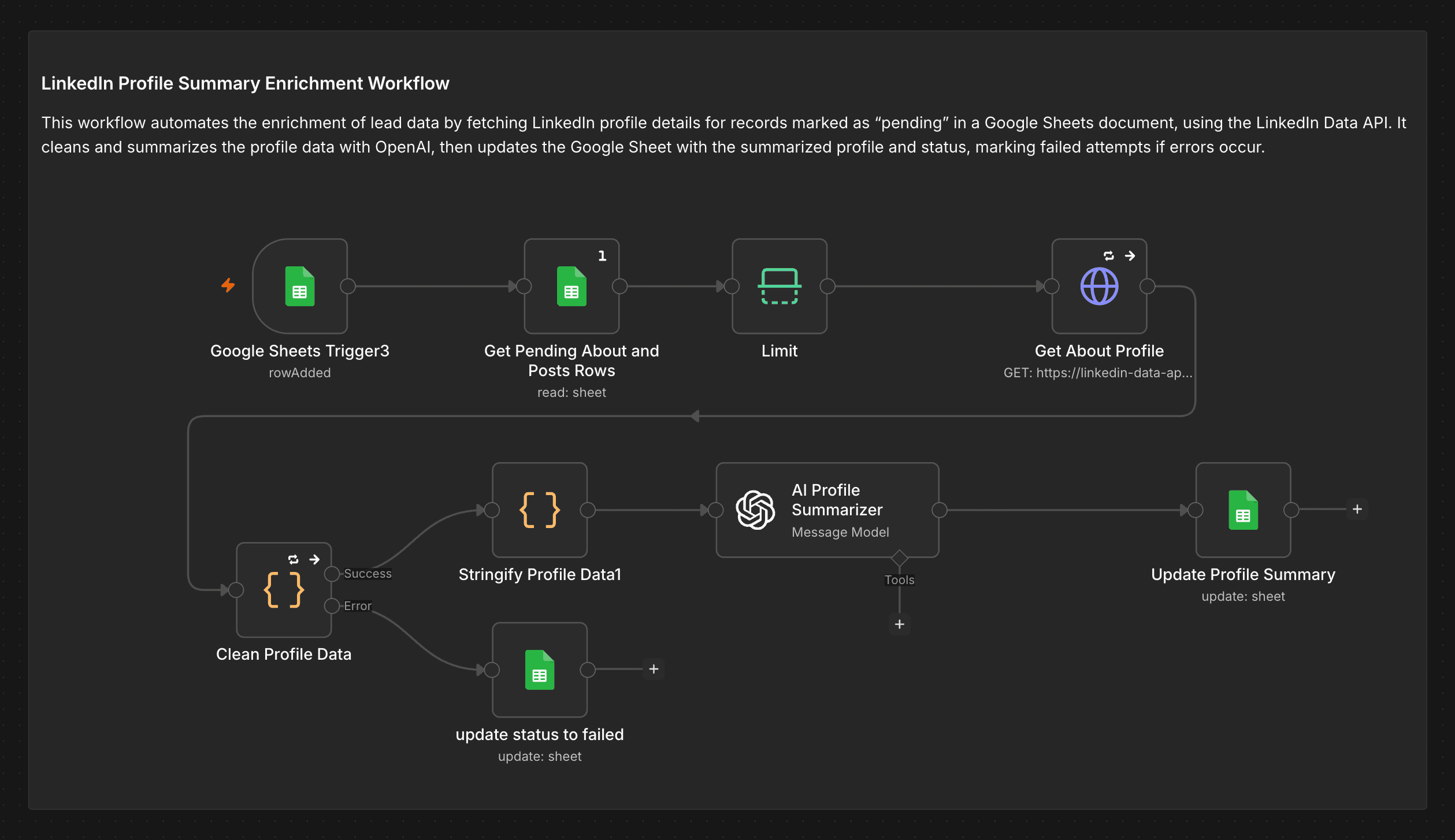
Pulls each lead's LinkedIn bio via RapidAPI and passes it through a custom OpenAI prompt, writing a concise outreach-ready summary back to the sheet automatically.
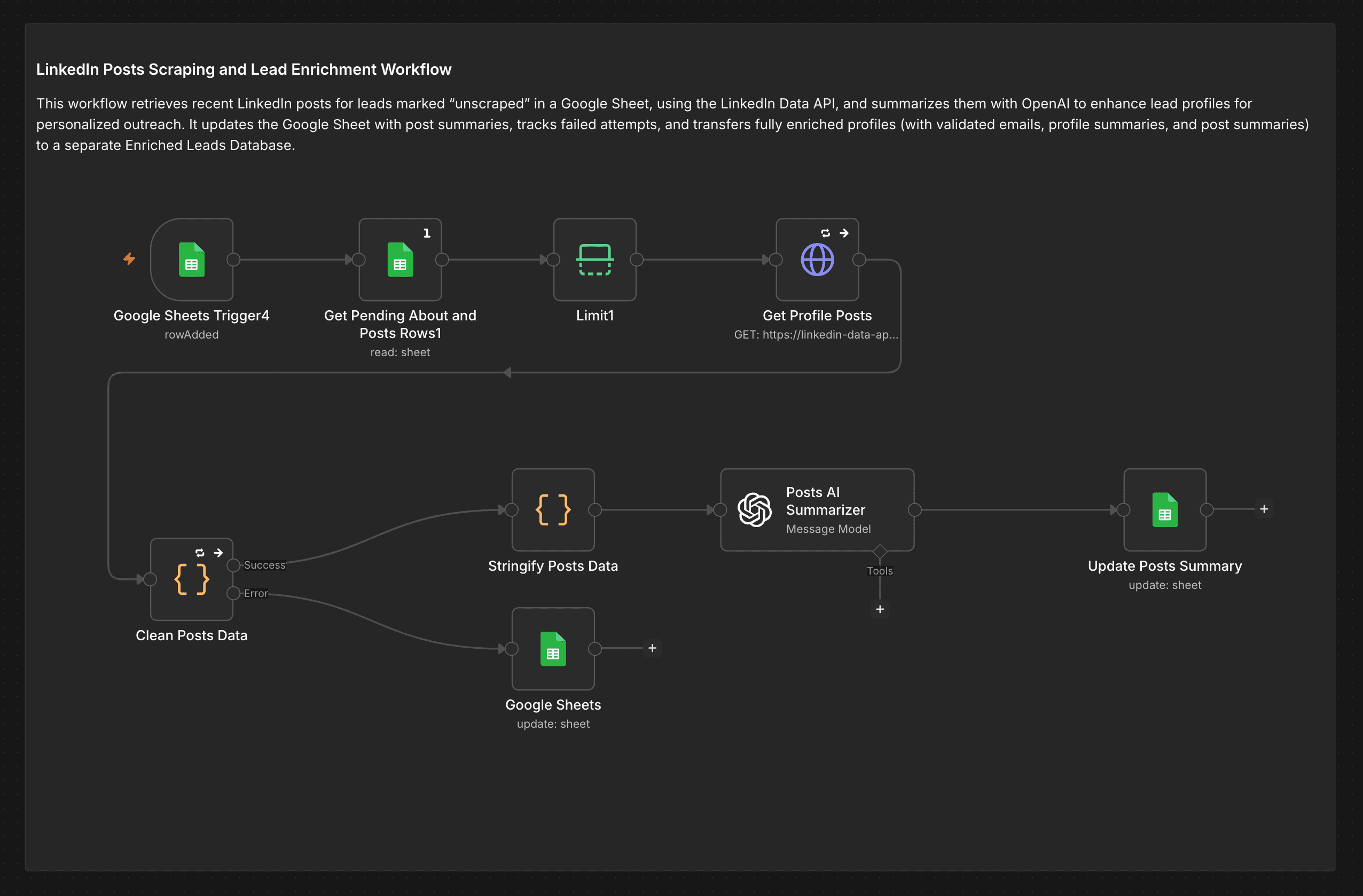
Scrapes each lead's recent LinkedIn posts and distils them into conversation hooks — so reps open with what the prospect cares about right now, not a generic opener.
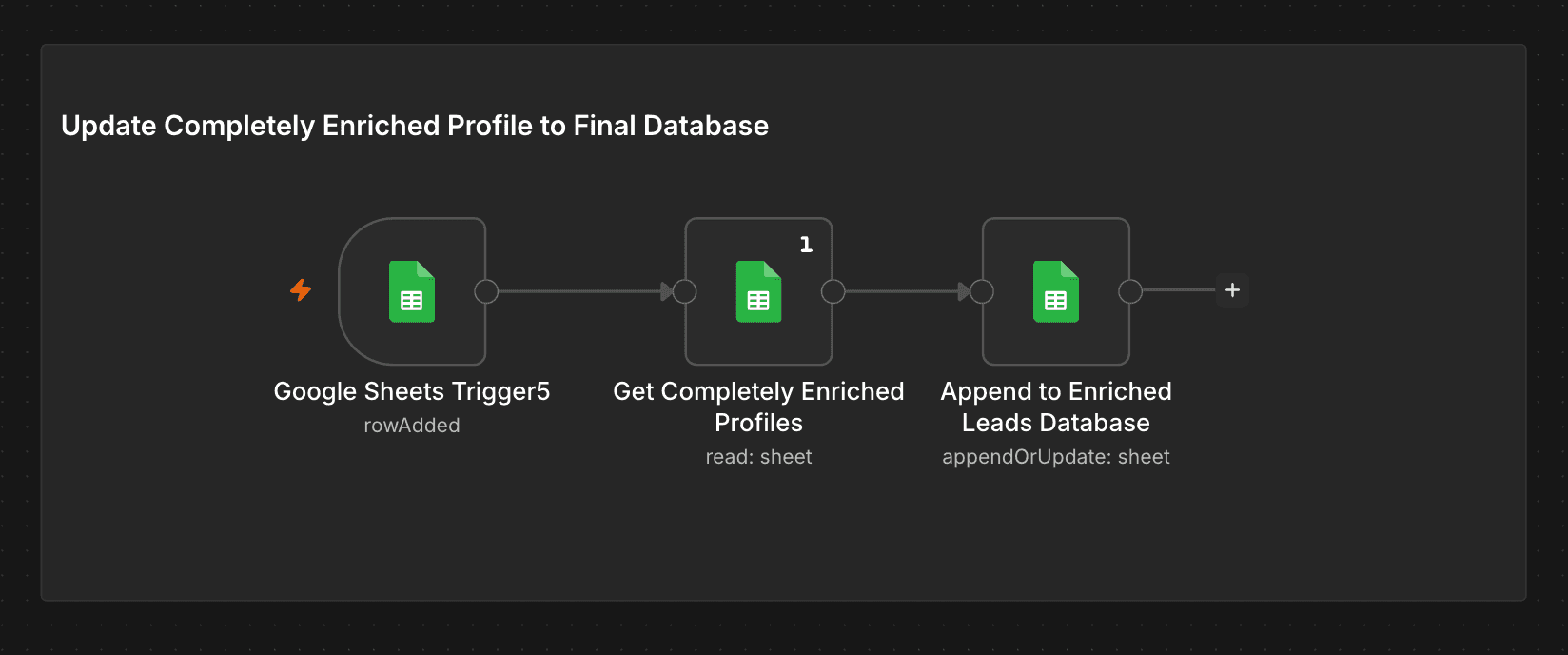
Once a lead is fully enriched, it's appended to a clean sales-ready sheet — the only view reps ever touch, separate from the status-tracking pipeline.
Before vs. After
Same Team.
Three Times the Volume.
Measured at 60 days post-launch. The headline number — 480 hours reclaimed per year — understates the impact, because those hours came from the team's most productive selling time.
Why These
Choices?
Three calls with real tradeoffs, and the reasoning behind each.
ZoomInfo or Lusha
over native LinkedIn API
a CRM or database
What I'd Do
Differently.
Three weeks to design, build, and calibrate. A few things I'd approach differently next time.
✗ Email validation should be the first step, not the third
In the first version, email validation happened after username extraction. That meant rows with invalid emails had already consumed username extraction credits before being filtered out. Moving mails.so validation earlier — immediately after Apollo email retrieval — would have saved enrichment budget and reduced the number of rows in the pipeline that were doomed from the start.
✗ RapidAPI rate limits needed explicit Limit nodes from day one
The first run hit RapidAPI rate limits within minutes because the workflow processed all pending rows simultaneously. Adding Limit nodes to cap rows per execution was a retrofit. Any workflow that calls a rate-limited external API should have explicit throughput controls built in before the first production run — not added after the first failure.
✗ LinkedIn URLs from Apollo weren't always valid
Apollo returned malformed or missing LinkedIn URLs for roughly 12% of leads — blank fields, company page URLs instead of personal profiles, or URLs with trailing parameters that broke username extraction. A URL validation and normalisation step should have been in the pipeline from the start, not added after discovering the failure pattern in week two.
✓ Separate workflows per enrichment stage was the right call
Keeping profile enrichment and posts scraping as independent workflows — each with their own trigger, status column, Limit node, and retry logic — meant a RapidAPI timeout on posts never blocked profile enrichment from completing. Modularity at the workflow level, not just the node level, is what made the pipeline debuggable and reliable in production.
Our reps used to spend half their morning just researching prospects. Now they open the sheet and the work is already done — bio, recent posts, verified email, ready to write.Sarah Okonkwo, Head of Sales — MarketStar